Share this
by David Brunner on Apr 2024
Our mission at ModuleQ is to help professionals achieve their goals by using state-of-the-art AI. We believe that the better AI understands your professional priorities, the more effectively it can help you achieve them. Large Language Models (LLMs) are the most dramatic advance in AI technology in decades, so we're keenly interested in how we can use LLMs to enhance the performance of ModuleQ’s Unprompted AI. Can LLMs enable AI systems like ours to achieve a deeper, more accurate understanding of your work?
The tendency of LLMs to respond eloquently to almost any question creates an impression of deep understanding. Unfortunately, it's not always clear whether that understanding is accurate, because LLMs are known to “hallucinate,” that is, to generate output that while statistically probable, turns out to be factually incorrect. Our research team recently set out to investigate LLM performance in the context of investment banking work. Specifically, they studied the ability of LLMs to understand analytical questions precisely and give complete, accurate answers.
This blog post summarizes the researchers’ key findings. More detail is available in their paper “Can LLMs answer investment banking questions?” The research team presented the paper at the AAAI-MAKE Symposium at Stanford University last month.
LLM performance fell far short of our expectations
The first research question was simple: how accurately do state-of-the-art LLMs understand basic analytical tasks that are common in the world of investment banking? The researchers developed a benchmark consisting of 16 relatively straightforward questions of the kind that a senior banker might ask an analyst, expecting a quick and accurate response. For example: how many companies did Microsoft acquire between 2014 and 2016, what was the total value of those acquisitions, how many of the targets were headquartered in a particular country, and which of the acquisitions were in a particular industry such as security or gaming? The researchers then asked mainstream LLMs and LLM-integrated search experiences, such as GPT-4, Microsoft Bing, and Google Generative Search Experience, to answer these questions.
Although the answers were often partially correct (see the figure below for examples), the overall accuracy was surprisingly low. In fact, none of the systems tested could answer more than one of the 16 benchmark questions correctly. What was perhaps most surprising was that the LLM-powered search tools actually cited a Wikipedia page containing all the information required to answer the questions. This suggests that the cause of poor performance was not lack of access to the necessary information, but rather the inability of the LLMs to correctly process and reason with this information.

Domain-tuned methods for improving LLM performance
The researchers then set out to understand how the performance of LLMs could be improved. One possible approach would have been to fine-tune an LLM with domain-specific training data or even train a domain-specific LLM using content relevant to the benchmark questions, as Bloomberg has done with BloombergGPT. Recent research sheds doubt on the power of this approach, finding that the most advanced general-purpose LLMs perform better on financial industry NLP benchmarks than LLMs specifically trained on financial content.
Instead, the researchers took a different approach, inspired by OpenAI function-calling and emerging “agent-like” LLM-based systems such as Smallville and MemGPT. This approach is to embed the LLM in a system called an “AI agent” that orchestrates LLM activity. The AI agent invokes the LLM with carefully designed prompts, interprets the LLM’s output, calls the LLM iteratively as needed, and returns responses back to the user. Components of the prompts provide the LLM with tools that perform tasks such as retrieving information, generating plans for solving problems or performing analyses, or reflecting on and improving prior responses. For more information about these AI agent design patterns, see this series of posts by Andrew Ng.
An “expert” AI agent designed for analyzing acquisition data
The AI agent constructed by the ModuleQ research team, depicted in the diagram below, prompts the LLM to make use, as it sees fit, of certain functions provided by the AI agent environment. The prompt describes the capabilities of these functions, which are designed to retrieve specific information from knowledge bases or information repositories (such as data about acquisitions matching specified criteria), to execute SQL queries to retrieve specific information from relational databases, or to create a plan for answering a question using a chain of thought reasoning.
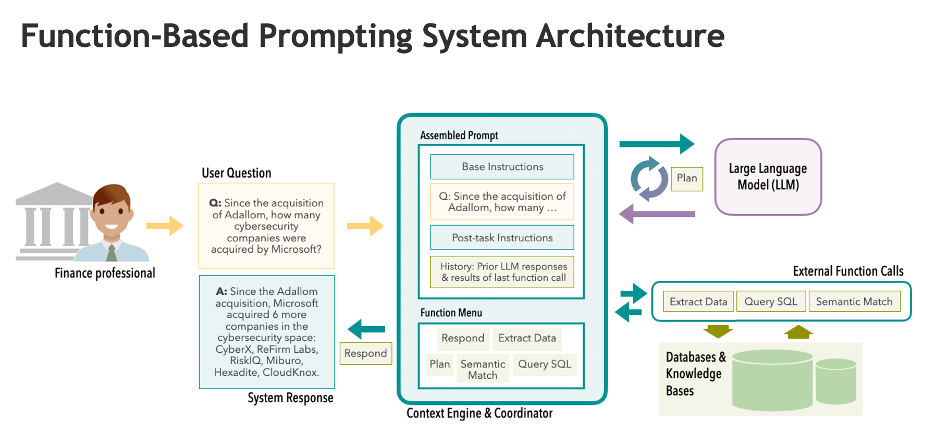
The functions provided to the LLM were specifically designed to help the LLM retrieve and analyze the acquisition data relevant to the questions in the benchmark. Although it would be an exaggeration to call the AI agent an “expert” on acquisitions, the researchers' approach has parallels to an earlier generation of AI systems called “expert systems.” These systems were widely acclaimed in the 1970s and 1980s for achieving expert-level performance in narrow domains. They worked by incorporating specialized knowledge and problem-solving methods.
Unlocking the power of LLMs with AI agent workflows
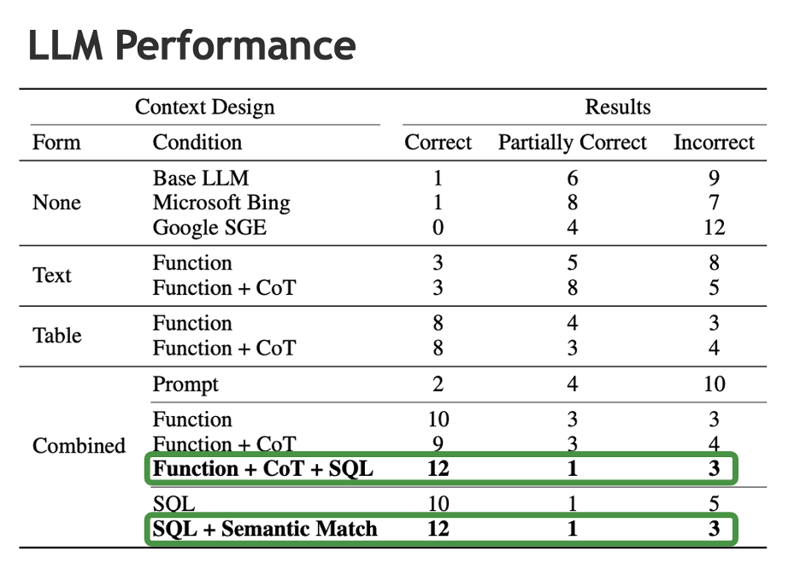
The results, shown in the table below, demonstrate that AI agent design patterns, used independently or in combination, can result in significantly higher domain-specific performance compared to a standalone LLM. The most effective AI agent designs achieved 75% accuracy, answering 12 out of the 16 benchmark questions correctly.
The implications for applied AI leaders are clear:
-
While 75% accuracy falls far short of the level required for important business decision-making, this research highlights the great promise of AI agent design patterns, because the relatively straightforward application of these techniques boosted accuracy dramatically from less than 10% to 75%.
-
AI agent workflows will need to be tuned to specific industries and professional tasks such as investment banking, asset management, pharmaceutical research, and so on.
-
Depending on the setting, high-performance AI agents may require highly specialized equipment including domain-tuned tools, knowledge bases, and analytical techniques.
For more information about this research or to speak with us about opportunities for applying AI and LLMs in your business, please contact me at djb@moduleq.com